
Your context shouldn’t live in ten places
No enterprise has one place for business logic. You have views in Looker, Omni, dbt, Snowflake Semantic views, and Power BI, each of which holds a slice of business logic someone fought hard to define. Every data leader we talk to raises the same fear about adopting a new agent: now there’s another context layer to maintain, and the definitions start to drift. The context layer needs to distill information from many separate systems, adapt itself over time as the business context changes, and synchronize those changes back to source systems.
When an operational agent fires on a “net sales” metric that doesn’t match the one your analysts use, that’s a wrong email to a real customer. The definitions already sitting in your tools are a goldmine for discovering how your business thinks. New agents should start there, not from zero.
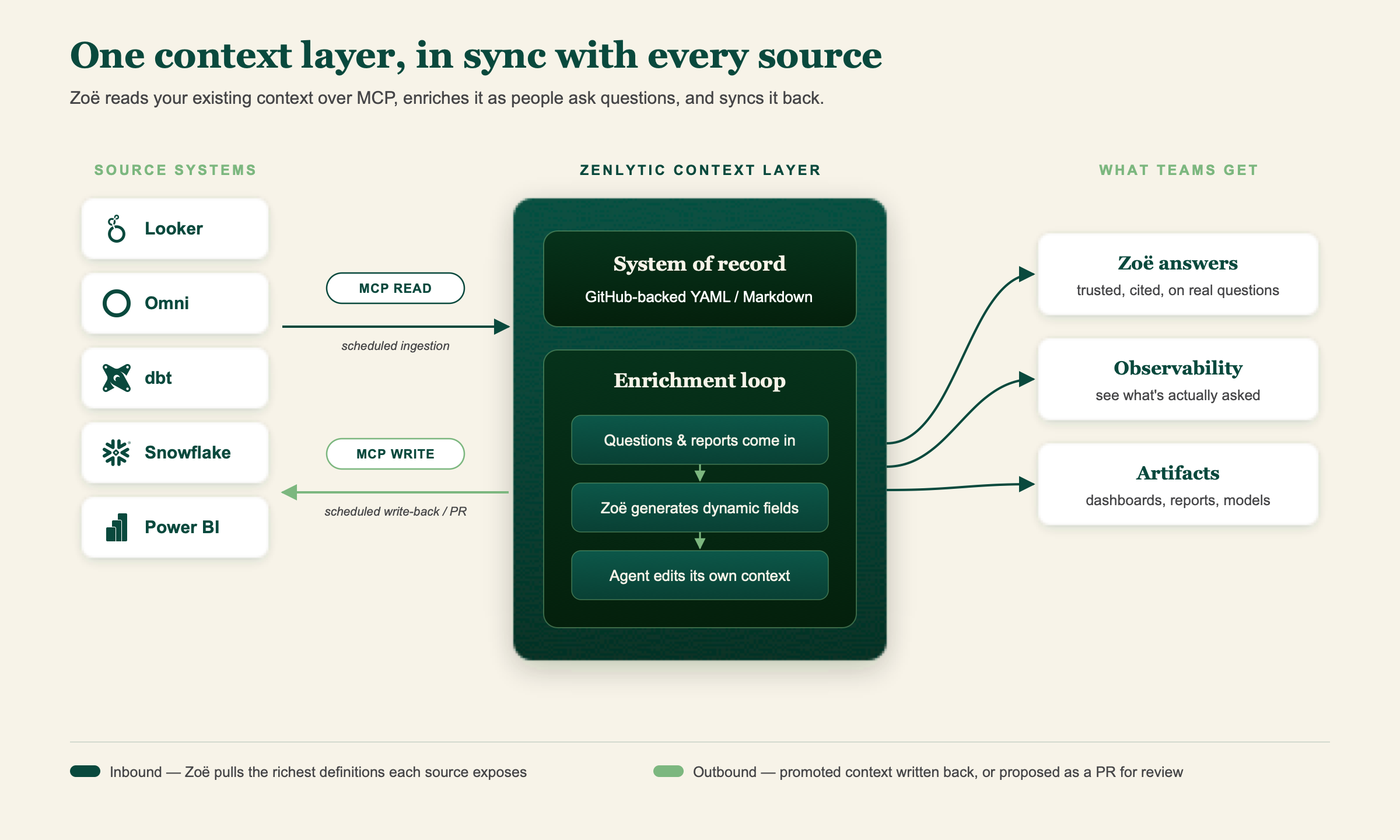
The unlock is closing the loop. Context flows in from the tools you already use, gets smarter as people ask real questions, and flows back to keep your sources current. Analytics and operations continue to reference the same definitions.
How it works
Zoë reads your existing context from your source systems over MCP and uses it to set herself up. There’s no manual rebuild. As people ask real questions, she improves her context, and the definitions worth keeping get promoted by a human in the loop. Then the verified context syncs back to your source of record, and because those sources are now richer, the next question starts from a better place. The loop runs on its own, and every pass makes the next one smarter.

Why centralize, rather than read from the source every time?
Scattered context results in a slow, untrusting agent. When the layer is unified, Zoë already knows where the right definitions live, rather than spending the first hour of every question rediscovering them across five systems.
It’s also where conflicts get resolved: when LookML says one thing and a dbt model says another, the central layer settles on one truth. Reading live from each source just re-inherits the disagreement every time.
Finally, the agent needs a home of its own to think in: a place to edit its context and update its memory as it learns, without writing back to source systems on every change, which could leave it with nowhere to put the context it needs to answer questions accurately.
1. Ingestion: Pulling context in
Zoë connects to your source systems as an MCP client and pulls in definitions, relationships, descriptions, and lineage. A scheduled agent runs this on a cadence, so the sync stays current on its own. She taps the richest definitions each tool exposes through its MCP interface and the underlying context in your source repos (dbt, LookML, etc), where the real depth lives. Everything she pulls is written into her own context using the same self-modeling she uses to maintain her context layer.
2. One system of record
Zoë’s context all normalizes into a single GitHub-backed layer of YAML and Markdown with definitions, relationships, skills, and the rest of the context that powers Zoë’s answers. The distinction between verified and dynamic fields is preserved throughout, so you always know what’s officially governed vs. what the agent generated on the fly.
3. Context that learns
As users ask questions, Zoë generates dynamic fields to answer what isn’t modeled yet. Observability surfaces what people are actually asking, the revealed priorities, not just the ones someone wrote down. The agent learns from those questions and from the reports it’s handed, editing its own context to standardize over time. The agent can build and maintain its own context layer, while the data team has clear visibility into what the business is asking.
4. Keeping your sources current
A scheduled agent handles writing back to other systems on the same cadence as ingestion. Depending on how your MCP server is set up and the governance process you want, Zoë can either write verified context straight back to your source of record or propose it as a change for review in a pull request against your repo. With either approach, the layers you already maintain stay in sync with what Zoë has learned.
Start one-way, then close the loop
You don’t have to turn it all on at once. Start with ingestion: pull from your existing context sources so Zoë is useful on day one, and learns your business without a rebuild. Add writeback once you trust the loop so your verified context flows back to its sources.
Download our one-page guide now.